Hello Framers! Below is a FrameMaker autonumber primer on video. If you are a new FrameMaker user, this will give you a 20-minute overview of autonumbers and how they work. This is the first in my “antiwebinar” series. No forms to fill out, no fancy slides, just (mainly) unedited content that you can view whenever you want. You may hear some doors slamming in the background or my creaky chair, but I will get straight to the point so you can learn something. As always, I value your questions and comments. -Rick
RunaroundNone Released as an ExtendScript Script
My plugin, RunaroundNone, has been rewritten as an ExtendScript script for FrameMaker 10 or higher. It changes the default Runaround Properties on imported graphics to “Don’t Run Around.” When graphics are imported into FrameMaker, their Runaround property is normally set to “Run Around Contour.”
This can cause callout text frames placed on top of graphics to behave strangely; for example, the text can disappear or be displaced in the text frame. This makes sense because the purpose of “Run Around” is to cause text to flow around a graphic in a FrameMaker layout. In reality, though, this is a seldom used feature in FrameMaker and it is surely not what you want when you are placing callout text on top of a graphic inside an anchored frame. So it is best to have this set to “Don’t Run Around” for your imported graphics.
RunaroundNone automatically takes care of this for you whenever you import a graphic. For existing graphics, RunaroundNone adds a new command under the Graphics menu to set all of them to “Don’t Run Around” at once. Click here to see the documentation. RunaroundNone is only $19 and is available at our online store.
ArchiveES Released
ArchiveES is an ExtendScript script for archiving a FrameMaker book or document. It is patterned after the original Archive plugin written by the late Bruce Foster, a long-time contributor to the FrameMaker community. When you run the script, it will prompt you for an archive folder, or allow you to create a new folder. It will create Graphics and Insets folders inside of the archive folder and will copy the book or document and its referenced files into this folder and Graphics and Insets subfolders. All references, including graphics, text insets, and external cross-references will be updated to point to the archived folders so that the archived book or document will be self-contained within the archive folder. Click here to see the documentation.
ArchiveES works with FrameMaker 10 and higher and does NOT require FrameScript. It is available for only $39 from my store.
See all of your cross-references with CrossrefReporter
Do you need to see all of the cross-references in your book in one place? You can now with CrossrefReporter. CrossrefReporter is an ExtendScript script that creates a table of all of the cross-references in a book. Each row displays the document name, the cross-reference text, and the page number of the cross-reference. Not only that, but you will see the name of the document containing the companion Cross-Ref marker and its page number. There are hyperlinks to both the cross-references and the markers so you can quickly navigate to them. The report table can be sorted and edited to make it more useful to you.
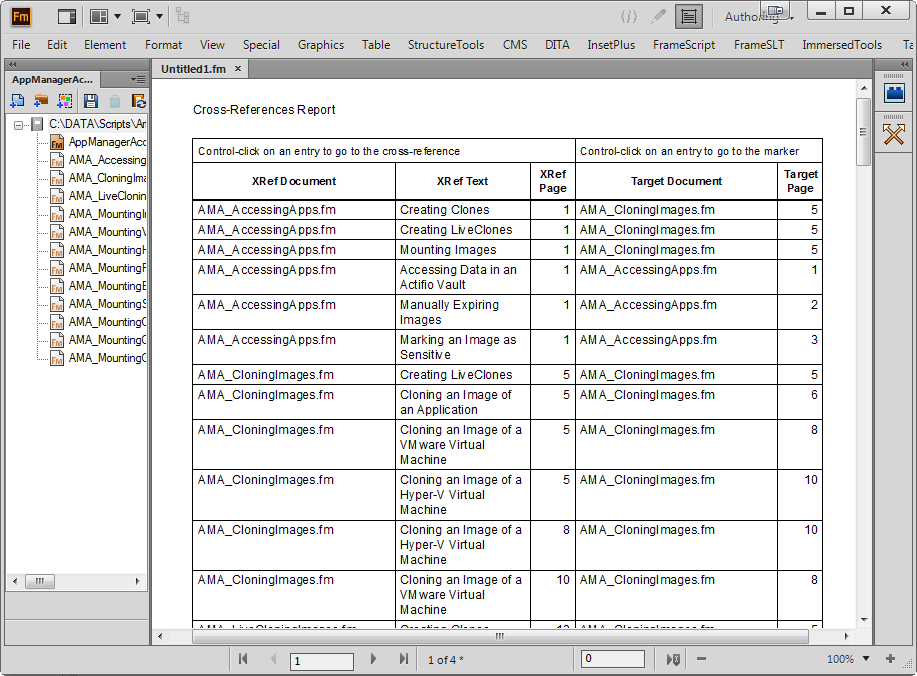
In addition, you can select a Cross-Ref marker in a document and generate a report of all cross-references in the book that point to it. This is useful when you want to delete content that contains Cross-Ref markers and want to make sure you don’t leave unresolved cross-references.
CrossrefReporter works with FrameMaker 10 or higher and DOES NOT require FrameScript. CrossrefReporter is only $19 and is available at my online store. You can download the documentation here.
Ride for Roswell 2016
Rick and Jason have reached their fundraising goals. If you would like to purchase any of the scripts, please go to our online store.
It’s time for the Annual Ride for Roswell bike event to raise money for cancer research at the Roswell Cancer Institute in Buffalo. My son Jason and I are riding the 102 mile route again this year. This year, I have decided to make some of my ExtendScript scripts available in exchange for a donation to the ride. And, you can donate any amount you want for each script! ExtendScript is built into FrameMaker 10 and higher. Here is a brief description of each script:
TableCleanerES: This is the new and improved version of my TableCleaner plugin. Some of the batch commands can now be performed on all of the files in a book! Click here for details.
PathChanger: This script allows you to manage paths for graphics, text insets, external cross-references, and book components with an Excel spreadsheet. You need this script when you rename or move referenced files. Click here for details.
FindChangeFormatsBatch: This script allows you to Find/Change hundreds of FrameMaker formats in a document or book with a single command. Formats are specified in a simple FrameMaker table. Click here for details.
PageLabelerES: The ExtendScript version of a long-time favorite. Transfers your FrameMaker book’s numbering to your PDF file. Click here to download the documentation.
ImportFormatsSpecialES: This script allows you more granular control of the document properties that you import from a template. It also allows you to import User Variables without System Variables and vise versa so you can import one type of variable format without clobbering the others. Click here to download the documentation.
Thank you for your generosity!
InDesign Table of Contents Webinar – Thursday, January 28, 2016, 1:00 pm EST
I am conducting an informal Webinar titled: “Generating custom InDesign Tables of Contents using XML, XSLT, and Tagged Text”. Sometimes you need a complex table of contents or index that can’t be easily generated using InDesign’s built-in Table of Contents command. I will demonstrate a simple workflow using XML, XSLT, and InDesign Tagged Text. Here is the registration information:
Please register for InDesign Table of Contents Webinar on Jan 28, 2016 1:00 PM EST at:
https://attendee.gotowebinar.com/register/1720368832769140482
Sometimes you need a complex table of contents or index that can’t be easily generated using InDesign’s built-in Table of Contents command. Rick Quatro, long-time automation expert, will demonstrate a simple workflow using XML, XSLT, and InDesign Tagged Text.
After registering, you will receive a confirmation email containing information about joining the webinar.
Here are the Webinar notes.
Solving Path Problems with PathChanger
Let’s face it, the FrameMaker documents that we work with rarely stand alone. They often have graphics imported by reference, text insets, and external cross-references, all pointing to files outside of the FrameMaker document. FrameMaker books point to book components that can be located just about anywhere. And when files get moved or renamed, we can end up with a combination of missing graphics, unresolved text insets, unresolved cross-references, or books with missing components.
A FrameMaker document or book stores paths internally for each of these items. PathChanger is a series of ExtendScript scripts that makes it easy to change these paths for a FrameMaker document or book. It has a command for extracting and writing these paths to a simple .csv file. This file can be opened with Excel where you can easily see and edit and change the paths. Once the paths are updated, another command applies them back to the FrameMaker document or book, quickly resolving the missing or unresolved objects. There are additional commands for writing and updating books and their paths to each book component.
Here is how it works for imported graphics, text insets, and external cross-references:
- Open the document or book that has paths that need to be updated.
- Choose File > Utilities > Write Paths to File. The script will write the path information to a paths.csv file in the same folder as the document or book.
- Open the paths.csv file with Excel and edit the Path column in any rows that you want to update. Do not change any of the information in the other columns. You can delete any rows from the csv file that you don’t want to update.
- Save the edited Excel file. The file must by saved as a csv file, not as a native xls or xlsx file.
- Choose File > Utilities > Update Paths.
- Choose the updated csv file that you saved in step 4. PathChanger will open the files listed in the csv file and update the paths.
The process is similar for updating book component paths:
- Open the book that has book component paths that need to be updated.
- Choose File > Utilities > Write Book Component Paths to File. The script will write the book component paths information to a book_components_paths.csv file and save it in the same folder as the book.
- Open the book_components_paths.csv file with Excel and edit the Path column in any rows that you want to update. Do not change any of the information in the other columns. You can delete any rows from the csv file that you don’t want to update.
- Save the edited Excel file. The file must by saved as a csv file, not as a native xls or xlsx file.
- Choose File > Utilities > Update Book Component Paths.
- Choose the updated csv file that you saved in step 4. PathChanger will update the book component paths in the book.
Download the documentation for more details on this powerful new program. Purchase PathChanger today for only $79 at our online store.
FindChangeFormatsBatch
FindChangeFormatsBatch is an ExtendScript script for FrameMaker 10 and higher. It allows you to Find/Change hundreds of FrameMaker formats in a document or book with a single command. It is controlled by a simple FrameMaker table that you fill in with your find/change formats. You can change the following format types: paragraph, table, character, condition, master page, marker type, cross-reference, and user variable. You can also use FindChangeFormatsBatch to delete unwanted formats from your document or book. FindChangeFormatsBatch is available now for $79 US. For more information, view the documentation. To purchase it, go to our online store.
Introducing TableCleanerES
FrameMaker and Word have always had an awkward relationship to each other. Technical writers are often required to integrate Word content into their FrameMaker publications. They soon learn that there is not always a one-to-one correspondence between the programs’ features. TableCleaner was designed to help users format FrameMaker tables that were imported from Word. The original TableCleaner, released in 1999, focused on two tasks: removing custom ruling and shading from tables and converting body rows to heading rows.
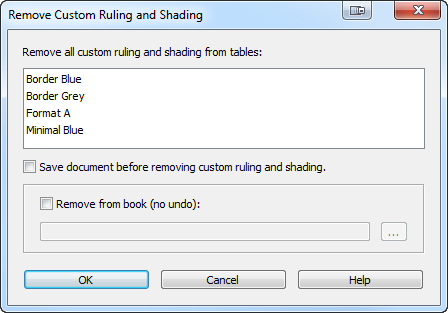
Some tables originating in Word have custom ruling and shading applied to them and that prevents ruling and shading changes applied from the Table Designer from appearing. So TableCleaner gives you a quick way to remove custom ruling and shading from all of the tables in a document. (NOTE: Screenshots are from the latest version of TableCleaner.)
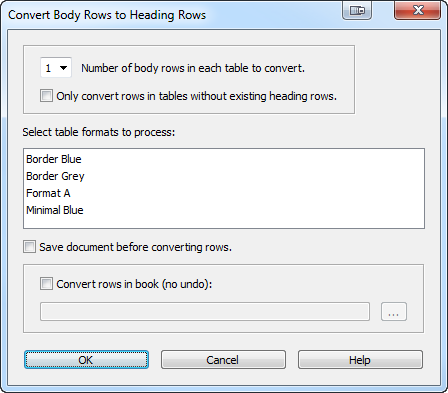
The second issue is heading rows; tables imported from Word do not have true FrameMaker header rows that repeat at the top of each new column and page. Manually converting the first row to a heading row is a multi-step process, so TableCleaner gives you a batch command for converting the first row in all of the tables in the document.
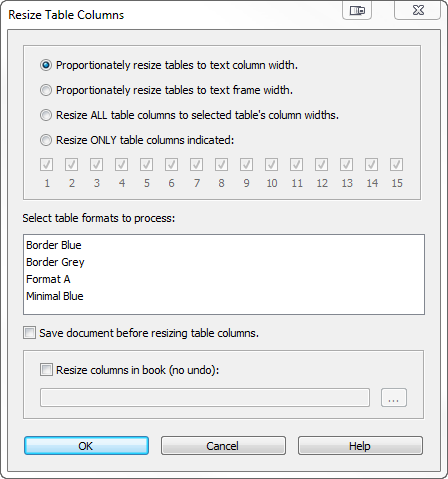
Over time, I added more goodies to TableCleaner that are useful regardless of where the tables originated from. One popular feature is the ability to resize multiple tables with a single command. This includes an option to resize “by example”; you resize a single table to your liking and then apply this sizing to a bunch of other tables with a single command.
TableCleaner was originally written as a FrameMaker plugin, but I have recently rewritten it in ExtendScript. ExtendScript is Adobe’s implementation of JavaScript and it is built into FrameMaker 10 and higher. There are two significant new features: batch commands can now be applied to all of the documents in a book. And the interface can now be localized through a simple XML file. TableCleanerES is available now for only $39 US. Check out the full documentation, or purchase it now at my online store.
PostScript Text Frames
We had our first informal FrameMaker webinar on December 10, 2015. It was graciously hosted by Vivek Kumar of Adobe Systems via Adobe Connect. The topic was PostScript Text Frames and it was presented by me, Rick Quatro. Here is a link to the recording:
https://my.adobeconnect.com/p3y66svbtfr/
During the webinar I mentioned some useful resources for further learning:
- pdfmark Reference. This document explains pdfmark syntax, which is a PostScript language extension. pdfmark is used to produce Acrobat features, such as links, bookmarks, and buttons during the distilling process.
- Microtype.com. Microtype makes TimeSavers which is a fantastic program for adding Acrobat features with Hypertext markers instead of PostScript text frames. I have used this program for years and highly recommend it.
- Summary by Klaus Daube. Klaus is FrameMaker’s unofficial historian and has documented the nooks and crannies of the FrameMaker world.
If you have any comments or questions about PostScript Text Frames, please leave a comment below. Let me know if you have suggestions for further webinars.